制約ベース手法との違い と 関数型因果モデル(FCM)
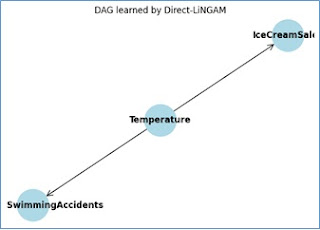
次のコード例では、 データ生成時に依存関係を強めに設定しているので、因果関係が検出されやすいようにしています。 bn.structure_learning.fit で direct-lingam を使って構造学習を行います。 学習結果の隣接行列から、エッジが (from, to) の形で存在するか(値が 0 以外の場合)をチェックしてエッジリストを作成します。 各ノードに対して、その親ノードからの影響(回帰係数)を OLS 回帰で推定し、エッジごとのスコアとして出力します。 以下のコードをご確認ください。 python import numpy as np import pandas as pd import bnlearn as bn import statsmodels.api as sm # ① データ生成(依存関係を強化) np.random.seed(42) n_samples = 300 temperature = np.random.uniform(20, 40, n_samples) ice_cream_sales = 5 * temperature + np.random.normal(0, 1, n_samples) swimming_accidents = 2 * temperature + np.random.normal(0, 1, n_samples) data = pd.DataFrame({ 'Temperature': temperature, 'IceCreamSales': ice_cream_sales, 'SwimmingAccidents': swimming_accidents }) # ② bnlearn による構造学習( direct-lingam を利用) model = bn.structure_learning.fit(data, methodtype='direct-lingam') # model['adjmat'] ...


